Artikel vom 22. Mai 2026
KI & Wissensmanagement
Wie Sie internes Wissen souverän nutzbar machen
Generative KI hat sich in deutschen Unternehmen schneller verbreitet als die Strukturen, die ihren Einsatz steuern könnten. Cloud-KIs liefern beeindruckende Antworten auf allgemeine Fragen, scheitern aber bei der entscheidenden Disziplin: dem zuverlässigen Arbeiten mit dem eigenen Unternehmenswissen — Verträgen, Studien, Fallakten, Konstruktionsdaten, Verfahrensanweisungen. Genau dieser Bereich ist gleichzeitig der wertvollste und der sensibelste.
KI-Wissensmanagement ist die Disziplin, die diese Lücke schließt. Sie verbindet e mit dem eigenen Datenbestand, sodass Mitarbeiter präzise Antworten aus internen Quellen erhalten — mit Quellnachweis, mit respektierten Berechtigungen, ohne dass Daten das Unternehmen verlassen.
Dieser Leitfaden zeigt IT-Leitern, KI-Verantwortlichen und Operations-Führungskräften, was KI-Wissensmanagement technisch und organisatorisch ausmacht: welche Architekturansätze tragfähig sind, welche Quellen erschlossen werden sollten, warum Rechtemanagement das am häufigsten unterschätzte Thema ist und wie ein produktives, souveränes System aussieht.
Lesezeit: ca. 16 Minuten | Zuletzt aktualisiert: Mai 2026
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
- 1. Was ist KI-Wissensmanagement?
- 2. Drei Treiber: Warum jetzt
- 3. Drei Wege zur lokalen KI im Vergleich
- 4. RAG-Architektur verstehen
- 5. Konnektoren-Strategie: Welche Quellen, in welcher Reihenfolge
- 6. Rechtemanagement: Das übersehene Thema
- 7. Referenzarchitektur souveränes KI-Wissensmanagement
- 8. Erfolgsmessung und ROI
- 9. 90-Tage-Handlungsleitfaden
- 10. Häufige Fragen (FAQ)
1. Was ist KI-Wissensmanagement? #
KI-Wissensmanagement bezeichnet den Einsatz generativer KI, um internes Unternehmenswissen für Mitarbeiter abrufbar und produktiv nutzbar zu machen. Drei Eigenschaften unterscheiden es von einfacher KI-Nutzung:
Verankerung in eigenen Daten. Antworten basieren nicht auf dem allgemeinen Trainingswissen des Sprachmodells, sondern auf konkreten Dokumenten aus dem Unternehmen — Verträgen, Berichten, Wikis, Akten. Das Modell formuliert, die Quellen liefern die Inhalte.
Quellnachweis. Jede Antwort verweist auf die Originaldokumente, aus denen sie stammt. Mitarbeiter können nachvollziehen, woher eine Information kommt, und sie im Originaltext überprüfen.
Berücksichtigung von Berechtigungen. Die KI antwortet nur auf Basis von Inhalten, auf die der fragende Nutzer Zugriffsrechte hat. Personalakten, M&A‑Unterlagen, NDA-Dokumente bleiben für Unbefugte unsichtbar — auch dann, wenn sie technisch indiziert sind.
Damit ist KI-Wissensmanagement deutlich mehr als ein Chatbot. Es ist eine Informationsinfrastruktur, die Suche, Sprachverständnis und Berechtigungslogik zu einem System verbindet.
2. Drei Treiber: Warum jetzt
KI-Wissensmanagement ist kein neuer Begriff, aber die Umsetzungsdringlichkeit ist 2026 deutlich gestiegen. Drei Treiber wirken zusammen.
Wettbewerbsdruck. Unternehmen, die KI produktiv einsetzen, verkürzen Recherche-, Erstell- und Entscheidungszeiten erheblich. Eine Studie der Federal Reserve Bank of St. Louis (Bick, Blandin, Deming, Erhebung November 2024) ermittelt eine durchschnittliche Zeitersparnis von rund 5,4 % der Wochenarbeitszeit bei regelmäßigen Nutzern generativer KI. McKinsey zitiert diese Zahl in „Superagency in the Workplace" 2025. Wer keine geprüfte KI-Lösung bereitstellt, verliert diesen Produktivitätsvorsprung — oder akzeptiert, dass Mitarbeiter ihn über Schatten-KI selbst herstellen.
Compliance-Lock. , und schaffen eine Lage, in der Cloud-KI für regulierte Daten faktisch ausgeschlossen ist. Gleichzeitig zwingen Artikel 4 des (KI-Kompetenzpflicht, anwendbar seit Februar 2025) und Verarbeitungsverzeichnis-Pflichten der Unternehmen dazu, ihre KI-Nutzung offenzulegen und zu steuern. Eine offizielle, geprüfte interne Lösung ist die einzig saubere Antwort.
Implementierungslücke. Laut McKinsey-Daten haben 88 % der Unternehmen KI in mindestens einer Funktion eingeführt — aber nur ein Bruchteil davon erreicht messbare Geschäftsergebnisse. BCG fand, dass rund 60 % der Unternehmen aus ihren KI-Investitionen bisher keinen wesentlichen Wert erzielen. Der Grund ist meist nicht das Modell, sondern die Anbindung an die eigenen Daten und Prozesse. Wer KI-Wissensmanagement systematisch aufbaut, schließt diese Lücke.
EU AI Act
Der EU AI Act ist die weltweit erste umfassende gesetzliche Regulierung von KI-Systemen, in Kraft seit August 2024. Er klassifiziert KI-Anwendungen nach Risikoklassen und stellt an Hochrisiko-Systeme konkrete Anforderungen an Transparenz, Kontrolle, Datenschutz und menschliche Aufsicht.
EU AI Act
Der EU AI Act ist die weltweit erste umfassende gesetzliche Regulierung von KI-Systemen, in Kraft seit August 2024. Er klassifiziert KI-Anwendungen nach Risikoklassen und stellt an Hochrisiko-Systeme konkrete Anforderungen an Transparenz, Kontrolle, Datenschutz und menschliche Aufsicht.
DSGVO
Die DSGVO (Datenschutz-Grundverordnung, EU 2016/679) ist die europäische Regulierung zum Schutz personenbezogener Daten — für IT-Infrastruktur besonders relevant in Art. 5 (Grundsätze), Art. 17 (Recht auf Löschung), Art. 28 (Auftragsverarbeiter) und Art. 32 (Sicherheit der Verarbeitung).
DORA
DORA (Digital Operational Resilience Act, EU 2022/2554) ist eine EU-Verordnung, die seit Januar 2025 für alle regulierten Finanzmarktteilnehmer gilt und konkrete Anforderungen an IKT-Risikomanagement, Backup-Systeme (Art. 11 und 12), Drittanbieter-Management (Art. 28–30) sowie Incident-Meldung stellt.
NIS2
Die NIS2-Richtlinie (EU 2022/2555) ist eine EU-Regulierung, die wesentliche und wichtige Einrichtungen zu konkreten Cybersicherheitsmaßnahmen verpflichtet — darunter nachweisbares Backup-Management, Krisenmanagement und Meldepflichten — mit persönlicher Haftung der Geschäftsleitung bei Versäumnissen.
Datensouveränität
Datensouveränität beschreibt die vollständige Kontrolle einer Organisation über ihre Daten: wo sie gespeichert werden, wer darauf zugreifen kann, welchem Rechtsrahmen sie unterliegen und ob sie jederzeit ohne Abhängigkeit von einem einzelnen Anbieter verfügbar sind.
3. Drei Wege zur lokalen KI im Vergleich #
Wer Cloud-KI für sensible Daten ausschließen will, hat technisch drei Optionen. Sie unterscheiden sich grundlegend in Aufwand, Wartung, Zukunftsfähigkeit und in der Frage, ob der Ansatz im Mittelstand überhaupt tragfähig ist.
3.1 Eigenes LLM trainieren #
Ein eigenes Sprachmodell auf Basis öffentlicher oder eigener Trainingsdaten. Maximale Spezialisierung, vollständige Kontrolle. In der Praxis nur für Großkonzerne mit eigener KI-Forschungsabteilung darstellbar.
Aufwand: Millionen-Euro-Investition für Hardware, Strom, Trainingsdaten, ML-Team. Trainingsläufe dauern Wochen bis Monate.
Risiko: Modell veraltet schnell. Die Open-Source-Modelle (Mistral, Llama, Qwen, Gemma) entwickeln sich quartalsweise weiter — ein selbst trainiertes Modell hängt nach wenigen Monaten hinterher.
Geeignet für: Forschungseinrichtungen, Großkonzerne mit eigener KI-Strategie und mehrjährigem Zeithorizont.
3.2 DIY mit lokalen LLMs #
Open-Source-Tools wie Ollama, LM Studio oder llama.cpp auf eigener GPU-Hardware. Eine RAG-Pipeline und Konnektoren werden selbst gebaut. Niedriger Einstieg, hohe Flexibilität für Entwickler.
Aufwand: Geringe Anfangsinvestition in Hardware. Aber: Konnektoren, Rechtemanagement, Vektor-Datenbank, Audit-Trail, Modell-Updates müssen alle selbst implementiert und gepflegt werden.
Risiko: Skaliert nicht über den Prototypen hinaus. Sobald mehrere Quellen, Rechtemodelle und Nutzergruppen angebunden werden müssen, wird der Wartungsaufwand prohibitiv. Mit jedem neuen Modell, jedem M365-Update, jeder Berechtigungsänderung steigt die Komplexität.
Geeignet für: Einzelanwender, Forschungs- und Entwicklungsabteilungen, Prototyping. Nicht für produktiven Unternehmensbetrieb mit Compliance-Anforderungen.
3.3 Managed Appliance #
Fertige Hardware mit lokalem Inferencing, professionellem RAG-Stack, Vektor-Datenbank, Konnektoren-Bibliothek, AD-Integration und Wartungsvertrag. Der Anbieter pflegt Modell-Updates, Konnektoren und Sicherheits-Patches.
Aufwand: Höhere Einstiegsinvestition als DIY. Aber planbare TCO ohne nutzungsabhängige Token-Kosten und ohne eigenes Betriebsteam.
Risiko: Geringere Tuning-Freiheit als bei einem eigenen LLM. Dieser Punkt ist für die meisten Mittelstandsanwendungen unkritisch, weil die produktiven Use-Cases — Recherché, Zusammenfassung, Quellfindung — keine Modell-Spezialisierung erfordern.
Geeignet für: Mittelstand, Behörden, regulierte Branchen, alle Organisationen ohne eigenes KI-Forschungsteam.
| Kriterium | Eigenes LLM | DIY-LLM | Managed Appliance |
|---|---|---|---|
| Anfangsinvestition | Millionenbereich | Niedrig | Mittel |
| Deployment-Zeit | Monate bis Jahre | Wochen bis Monate | Tage bis Wochen |
| Betriebsaufwand intern | Sehr hoch | Hoch | Niedrig |
| Modell aktuell halten | Selbst | Selbst | Anbieter |
| Konnektoren | Selbst bauen | Selbst bauen | Mitgeliefert |
| Rechtemanagement | Selbst bauen | Selbst bauen | Integriert |
| Audit-Trail | Selbst bauen | Selbst bauen | Integriert |
| SLA / Support | Intern | — | Vertraglich |
| Skaliert auf Unternehmensbetrieb | Ja, mit Aufwand | Schwer | Ja |
Die praktische Konsequenz: Für die überwiegende Mehrheit der Unternehmen ist die Managed Appliance der einzige Weg, der die Anforderungen an Compliance, Wartbarkeit und Produktivität gleichzeitig erfüllt.
→ Anwendung: Lokales KI-Wissensmanagement mit Silent AI
4. RAG-Architektur verstehen
(RAG) ist der Architektur-Standard für KI-Wissensmanagement. Das Konzept wurde 2020 von Patrick Lewis und Kollegen bei Facebook AI Research veröffentlicht und hat sich seitdem als robuste Methode etabliert, um e mit eigenem Wissen zu verbinden, ohne sie neu zu trainieren.
RAG kombiniert drei Komponenten:
Retrieval (Suche). Wenn ein Nutzer eine Frage stellt, sucht das System zunächst in einer Vektor-Datenbank nach Dokumenten, deren Inhalt semantisch zur Frage passt. Die Suche basiert nicht auf Stichwort-Matches, sondern auf der Bedeutung — eine Frage nach „Aufbewahrungsfristen für Personalakten" findet auch Dokumente, die das Wort „Aufbewahrungsfrist" nicht enthalten, aber das Thema behandeln.
Augmentation (Anreicherung). Die gefundenen Quelltexte werden zusammen mit der ursprünglichen Frage an das übergeben. Das Modell sieht damit nicht nur die Frage, sondern auch die relevanten Dokumente.
Generation (Antwort). Das formuliert eine Antwort, die sich auf die übergebenen Quellen stützt. Da die Quelltexte mitgegeben werden, lassen sich die zitierten Stellen direkt verlinken — en sind dadurch deutlich reduziert.
Zwei technische Bausteine sind dafür nötig:
Embeddings. Jeder Dokumentenabschnitt wird in einen mathematischen Vektor übersetzt, der seine Bedeutung repräsentiert. Ähnlich bedeutende Texte erhalten ähnliche Vektoren. Das ist die Grundlage der semantischen Suche.
Vektor-Datenbank. Speichert die Embeddings effizient und ermöglicht schnelle Ähnlichkeitssuchen über Millionen von Dokumenten. Die Vektor-Datenbank ist eine zentrale Komponente jedes ernsthaften KI-Wissensmanagement-Systems.
Der entscheidende Vorteil von RAG gegenüber dem Fine-Tuning eines Modells: Daten lassen sich jederzeit hinzufügen, ändern und entfernen. Ein neues Dokument ist sofort recherchierbar, ein zurückgezogenes Dokument ist sofort aus dem Index entfernt. Beim Fine-Tuning müsste das Modell jedes Mal neu trainiert werden.
RAG (Retrieval-Augmented Generation)
RAG ist eine KI-Architektur, bei der ein Sprachmodell nicht aus dem Gedächtnis antwortet, sondern Antworten aus einem definierten, kontrollierten Datenbestand abruft und auf dieser Basis generiert — wodurch Halluzinationen strukturell vermieden werden.
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
KI-Halluzination
KI-Halluzination bezeichnet das Phänomen, bei dem ein Sprachmodell sachlich falsche, frei erfundene oder nicht belegbare Aussagen produziert, die sprachlich überzeugend und plausibel klingen.
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
5. Konnektoren-Strategie: Welche Quellen, in welcher Reihenfolge #
Die größte Hürde beim KI-Wissensmanagement ist selten das Sprachmodell — es sind die Konnektoren zu den eigenen Datenquellen. Praktische Reihenfolge für den Aufbau:
Stufe 1 — Microsoft 365 und SharePoint. In den meisten Unternehmen liegt der überwiegende Teil des aktiv genutzten Wissens in M365 (SharePoint, OneDrive, Teams-Dateien, Exchange). Mit dem Anschluss von M365 ist ein großer Teil der wertvollsten Inhalte sofort verfügbar — vorausgesetzt, die Berechtigungen sind sauber. Genau das ist oft nicht der Fall (siehe Abschnitt 6).
Stufe 2 — Wiki- und Wissensplattformen. Confluence, Nextcloud, Notion oder andere kollaborative Plattformen enthalten Verfahrensanweisungen, Architekturentscheidungen, Onboarding-Material. Dieser Anschluss ist meist technisch einfach (offene APIs) und liefert hohen Nutzwert für Recherché.
Stufe 3 — Fileserver. NFS- und SMB-Shares enthalten oft das ältere, weniger gepflegte Wissen — gewachsene Strukturen, viele Versionen, gemischte Berechtigungen. Wertvoll für Recherchen mit historischer Tiefe, erfordert aber Sorgfalt bei der Berechtigungs-Spiegelung.
Stufe 4 — Strukturierte Daten. SQL-Datenbanken, ERP-Auszüge, CRM-Notizen. Hier braucht es spezialisierte Konnektoren, die strukturierte Daten in für RAG nutzbare Texte umwandeln.
Stufe 5 — Spezialsysteme. Dozuki, PLM-Systeme, branchenspezifische Plattformen (KIS, RIS, PACS im Gesundheitswesen). Häufig über REST-APIs anschließbar, manchmal über Datei-Export.
Stufe 6 — Webseiten und externe Quellen. Eigene Webseite, Lieferanten-Portale, Behörden-Webseiten. Für aktuelle Informationen ergänzend sinnvoll, aber kein Kernbestand.
Stufe 7 — Ad-hoc-Upload. Einzelne Dokumente, die nicht dauerhaft in einer Quelle liegen, sollten direkt im KI-System hochladbar sein. Das deckt Recherché-Aufgaben ab, die außerhalb des regulären Wissensbestands liegen.
Pragmatische Empfehlung: Stufen 1 bis 3 in den ersten 90 Tagen anbinden. Stufen 4 bis 6 in einem zweiten Schritt nach Bedarf. Stufe 7 von Anfang an, weil sie organisatorisch entlastet.
6. Rechtemanagement: Das übersehene Thema
Die häufigste und teuerste Fehlannahme beim KI-Wissensmanagement: „Unsere Berechtigungen sind in Ordnung." Sie sind es in den seltensten Fällen — und genau hier entstehen die größten Risiken.
Das Microsoft-Copilot-Beispiel. Microsoft selbst nennt überschießende Berechtigungen („oversharing") als wichtigsten Risikofaktor bei Copilot-Deployments. Copilot arbeitet innerhalb der bestehenden M365-Rechte und prüft nicht, ob ein Zugriff sachlich angemessen ist. Eine SharePoint-Site, die historisch auf „Anyone in the organization" gesetzt wurde, wird durch Copilot zur Quelle für jeden, der danach fragt. Microsoft empfiehlt vor jedem Copilot-Rollout einen vollständigen Berechtigungs-Audit über das eigene SharePoint Advanced Management.
Was in der Praxis passiert. Über die Jahre wachsen Berechtigungsstrukturen organisch. Mitarbeiter werden in Gruppen aufgenommen, scheiden aus, wechseln Rollen. Projekte werden mit weit gefassten Rechten gestartet und nie aufgeräumt. Ergebnis: Berechtigungen spiegeln nicht mehr das Soll, sondern eine Historie, die niemand mehr durchschaut.
Das Risiko bei KI. Bei klassischer Suche fällt eine zu weit gesetzte Berechtigung selten auf, weil Nutzer nicht aktiv danach suchen. Bei KI ist es anders: Eine Frage wie „Was wissen wir über Mitarbeiter X?" oder „Welche Vergütungsspannen sind im Unternehmen üblich?" trifft sofort jede überzogene Berechtigung — und legt sie offen.
Was souveränes KI-Wissensmanagement leistet. Drei Schichten arbeiten zusammen:
- Berechtigungs-Spiegelung. Beim Indizieren einer Quelle wird zu jedem Dokument festgehalten, wer Leserechte besitzt. Diese Information bleibt mit dem Embedding verknüpft.
- Anfrage-Zeit-Filter. Wenn ein Nutzer eine Frage stellt, filtert das System die Treffer vor der Antwortgenerierung: Nur Inhalte mit Leserecht für diesen Nutzer fließen in den Kontext.
- Audit-Trail. Jede Anfrage, jeder Quellnachweis und jede Antwort wird protokolliert. Fehlkonfigurationen werden über Auswertungen sichtbar — und korrigierbar.
Praktische Konsequenz. Vor jedem produktiven KI-Wissensmanagement-Rollout gehört eine Berechtigungs-Hygiene: Überschießende Sites identifizieren, „Anyone"-Links entfernen, verwaiste Arbeitsbereiche schließen, Gruppenmitgliedschaften prüfen. Diese Arbeit ist nicht Aufgabe der KI — sie ist Voraussetzung dafür, dass die KI ohne Schaden funktioniert.
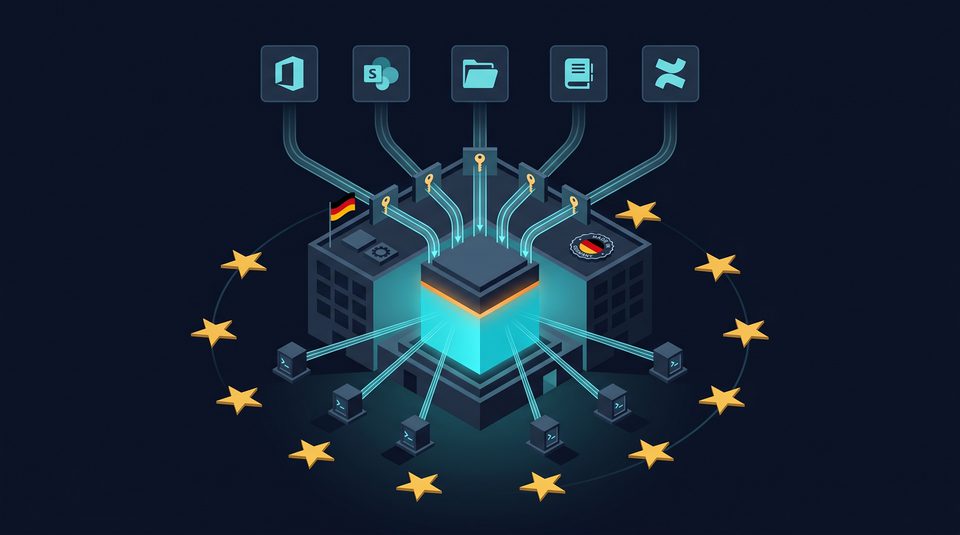
7. Referenzarchitektur souveränes KI-Wissensmanagement
Ein produktionsreifes System für souveränes KI-Wissensmanagement besteht aus sechs Schichten plus einem querliegenden Audit-Trail.
Die sechs Schichten im Überblick:
- Schicht 1 — Quellsysteme (bestehende IT): Lesender Zugriff auf bestehende Datenquellen, keine Datenkopie nötig.
- Schicht 2 — Konnektoren: M365, SharePoint, Exchange, Confluence, Fileserver (NFS/SMB), SQL, Nextcloud, Dozuki, Webseiten, Ad-hoc-Upload.
- Schicht 3 — Identität und Rechte: AD/LDAP-Integration, Rechte-Spiegelung pro Quelle und Dokument.
- Schicht 4 — Vektor-Datenbank: Embeddings aller indizierten Inhalte plus Berechtigungs-Metadaten pro Dokument.
- Schicht 5 — (Inferencing-Kern): Open-Source-LLM (Mistral, Qwen, Gemma) auf lokaler GPU-Hardware, RAG-Pipeline.
- Schicht 6 — Nutzer-Frontend: Browser-Oberfläche, Chat-Interface, optional Teams-Integration.
Querliegender Audit-Trail. Protokolliert pro Anfrage: Wer hat wann was gefragt, welche Quellen wurden gefunden, welche Antwort wurde generiert. Vollständig lokal, ohne externe Telemetrie. Erfüllt Art. 30 (Verarbeitungsverzeichnis), Art. 12/19 (Logging-Pflicht für Hochrisiko-Systeme bzw. allgemeine Nachvollziehbarkeit) und -Anforderungen an Nachvollziehbarkeit.
Souveränität-Anforderungen pro Schicht:
- Schicht 1 bis 2: Lesezugriff auf bestehende Systeme. Keine Migration, keine Datenkopie in Drittsysteme.
- Schicht 3: Bestehende AD/LDAP-Strukturen werden gespiegelt, nicht ersetzt.
- Schicht 4 bis 5: Vektor-Datenbank und laufen auf On-Premises-Hardware. Kein externer Inferencing-Dienst, keine Cloud-.
- Schicht 6: Nutzer-Frontend innerhalb des Unternehmensnetzwerks. Keine externe SaaS-Komponente im Anfragepfad.
- Audit-Trail: Vollständig lokal, ausreichend für -Verarbeitungsverzeichnis und -Risikomanagement.
Die Architektur erfüllt damit die drei Grundforderungen souveränen KI-Wissensmanagements: Daten bleiben im Haus, Berechtigungen werden durchgesetzt, jede Nutzung ist nachvollziehbar.
EU AI Act
Der EU AI Act ist die weltweit erste umfassende gesetzliche Regulierung von KI-Systemen, in Kraft seit August 2024. Er klassifiziert KI-Anwendungen nach Risikoklassen und stellt an Hochrisiko-Systeme konkrete Anforderungen an Transparenz, Kontrolle, Datenschutz und menschliche Aufsicht.
DSGVO
Die DSGVO (Datenschutz-Grundverordnung, EU 2016/679) ist die europäische Regulierung zum Schutz personenbezogener Daten — für IT-Infrastruktur besonders relevant in Art. 5 (Grundsätze), Art. 17 (Recht auf Löschung), Art. 28 (Auftragsverarbeiter) und Art. 32 (Sicherheit der Verarbeitung).
NIS2
Die NIS2-Richtlinie (EU 2022/2555) ist eine EU-Regulierung, die wesentliche und wichtige Einrichtungen zu konkreten Cybersicherheitsmaßnahmen verpflichtet — darunter nachweisbares Backup-Management, Krisenmanagement und Meldepflichten — mit persönlicher Haftung der Geschäftsleitung bei Versäumnissen.
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
LLM (Large Language Model)
Ein LLM ist ein KI-Modell, das auf großen Textmengen trainiert wurde und natürlichsprachige Anfragen versteht und beantwortet — Grundlage aller modernen KI-Assistenten, von ChatGPT bis zu lokal betriebenen Open-Source-Modellen.
Vektordatenbank
Eine Vektordatenbank speichert Texte und Dokumente als numerische Vektoren (sogenannte Embeddings) und ermöglicht semantische Suche — also die Suche nach inhaltlicher Bedeutung statt nach exakten Stichwörtern.
EU AI Act
Der EU AI Act ist die weltweit erste umfassende gesetzliche Regulierung von KI-Systemen, in Kraft seit August 2024. Er klassifiziert KI-Anwendungen nach Risikoklassen und stellt an Hochrisiko-Systeme konkrete Anforderungen an Transparenz, Kontrolle, Datenschutz und menschliche Aufsicht.
DSGVO
Die DSGVO (Datenschutz-Grundverordnung, EU 2016/679) ist die europäische Regulierung zum Schutz personenbezogener Daten — für IT-Infrastruktur besonders relevant in Art. 5 (Grundsätze), Art. 17 (Recht auf Löschung), Art. 28 (Auftragsverarbeiter) und Art. 32 (Sicherheit der Verarbeitung).
8. Erfolgsmessung und ROI
Eine wirtschaftliche Bewertung von KI-Wissensmanagement braucht mehr als das Versprechen einer abstrakten Produktivitätssteigerung. Vier Kennzahlen liefern belastbare Aussagen:
Zeit bis zur Antwort. Wie lange brauchen Mitarbeiter, um eine konkrete Information zu finden — vor und nach Einführung? Eine Reduktion von 15 Minuten Recherche auf 1 Minute KI-Antwort ist bei vielen Fragen realistisch und messbar.
Antwort-Qualität. Wie oft führt eine KI-Antwort tatsächlich zur Lösung — versus wie oft fragt der Mitarbeiter doch nochmal einen Kollegen? Diese Quote lässt sich über Stichproben oder Feedback-Buttons erheben.
Compliance-Reife. Wie viele Datenklassen sind durch die offizielle Lösung abgedeckt? Wie hoch ist der Anteil dokumentierter KI-Nutzung im Verarbeitungsverzeichnis? Eine vollständige Abdeckung ist messbar — und macht Schatten-KI strukturell unattraktiver.
Schatten-KI-Rückgang. Wiederholte Mitarbeiter-Umfragen (mit Amnestie) zeigen, ob die offizielle Lösung tatsächlich angenommen wird oder ob Schatten-KI weiterläuft.
Realistische Erwartungshaltung. Die St. Louis Fed-Studie (s. Abschnitt 2) misst rund 5,4 % Wochenzeit-Ersparnis bei regelmäßigen Nutzern generativer KI. Auf 50 Mitarbeiter mit 1.760 Jahresarbeitsstunden gerechnet entspricht das ungefähr 4.750 Stunden pro Jahr — in mittleren Stundensätzen zwischen 60 und 100 EUR ein erheblicher Wert. Wichtiger als die exakte Zahl ist die Erkenntnis: Der wirtschaftliche Effekt entsteht nicht durch das Tool, sondern durch konsequente Anbindung der eigenen Daten und durch Schulung der Mitarbeiter. Tools ohne Daten-Anbindung erzeugen Hype, aber keinen Wert.
9. 90-Tage-Handlungsleitfaden
Tag 1 bis 30: Voraussetzungen schaffen
Datenklassen definieren: Welche Daten dürfen in welche KI. Berechtigungs-Audit für die Top-3-Quellen (üblicherweise SharePoint, Fileserver, Confluence) durchführen. KI-Richtlinie entwerfen und Verarbeitungsverzeichnis ergänzen. KI-Kompetenz-Schulung gemäß Art. 4 aufsetzen.
Tag 31 bis 60: Pilot aufbauen
Managed Appliance evaluieren oder PoC starten. Pilot-Gruppe identifizieren (typisch: ein Fachteam mit klarem Wissensbedarf — z. B. Vertragsmanagement, Compliance, Service Operations). Konnektoren der Stufe 1 anbinden (M365, SharePoint). Erste Anfragen mit echten Use Cases durchspielen. Feedback einholen.
Tag 61 bis 90: Skalieren
Konnektoren Stufe 2 und 3 anbinden (Confluence, Fileserver). Zweite Nutzergruppe einbeziehen. Audit-Trail-Auswertung aufsetzen. Erste Berechtigungs-Drift-Analyse durchführen. Kommunikation an alle Mitarbeiter: Welche Lösung steht für welche Datenklassen zur Verfügung, was bleibt verboten — und warum die offizielle Lösung tatsächlich nützlich ist.
Nach 90 Tagen: Produktivbetrieb mit kontinuierlicher Erweiterung von Quellen, Nutzergruppen und Use Cases.
→ Anwendung: Lokales KI-Wissensmanagement mit Silent AI
EU AI Act
Der EU AI Act ist die weltweit erste umfassende gesetzliche Regulierung von KI-Systemen, in Kraft seit August 2024. Er klassifiziert KI-Anwendungen nach Risikoklassen und stellt an Hochrisiko-Systeme konkrete Anforderungen an Transparenz, Kontrolle, Datenschutz und menschliche Aufsicht.
10. Häufige Fragen (FAQ)
Copilot ist sinnvoll für unkritische Inhalte innerhalb der Microsoft-Welt, hat aber zwei strukturelle Schwächen für KI-Wissensmanagement im engeren Sinn: Erstens respektiert Copilot zwar SharePoint-Rechte, aber macht überschießende Berechtigungen sofort wirksam — eine schlecht konfigurierte Site wird sofort zur Datenquelle für alle. Microsoft empfiehlt deshalb einen vollständigen Berechtigungs-Audit vor jedem Copilot-Rollout. Zweitens ist Copilot Cloud-basiert — für regulierte oder besonders sensible Daten ist das nicht zulässig.
Technisch ja, die Open-Source-Bausteine sind verfügbar. Praktisch scheitern die meisten DIY-Projekte an Konnektoren, Rechtemanagement und Wartung. Ein PoC ist machbar, ein Produktivbetrieb mit Compliance-Anforderungen erfordert ein dauerhaftes Team.
Für KI-Wissensmanagement-Inferencing wird eine professionelle GPU mit ausreichend Speicher benötigt — der Bedarf hängt von Modell und Nutzeranzahl ab. Eine Managed Appliance liefert die Hardware mit der passenden Konfiguration. Wer DIY geht, sollte mindestens eine GPU der aktuellen Server-Generation einplanen.
Für die meisten Unternehmensszenarien sind Open-Source-Modelle wie Mistral, Qwen oder Gemma ausreichend leistungsfähig und in der Bedeutung gut beherrschbar. Wichtig ist, dass das Modell austauschbar bleibt — die Entwicklung läuft schnell, eine Festlegung auf ein einziges Modell ist riskant.
RAG reduziert en deutlich, weil das Modell auf konkrete Quellen zurückgreift. Aber sie sind nicht ausgeschlossen. Ein gutes System macht das transparent: Quellnachweise bei jeder Antwort, Markierung von Antworten ohne ausreichende Quellbasis, klare Hinweise an den Nutzer.
KI-Halluzination
KI-Halluzination bezeichnet das Phänomen, bei dem ein Sprachmodell sachlich falsche, frei erfundene oder nicht belegbare Aussagen produziert, die sprachlich überzeugend und plausibel klingen.
Im RAG-Modell ist das einfach: Dokument aus der Quelle entfernen, Reindexierung läuft. Bei nächster Anfrage ist das Dokument aus dem Treffer-Set verschwunden. Bei einem auf den Daten trainierten Modell wäre das wesentlich schwieriger.
Drei Kostenblöcke: Hardware (einmalig, je nach Anbieter und Konfiguration), Lizenzen (typisch in Paketen pro Anwender), Wartung (jährlich). Bei einer Managed Appliance ist die TCO planbar — keine nutzungsabhängigen Token-Kosten, keine Cloud-Rechnung. Konkrete Konditionen über das Sales-Team.